The paradigm of Artificial Intelligence has officially shifted. We are no longer building simple text-in, text-out chatbots. We are architecting autonomous agents that execute complex, multi-step workflows. But traditional inference is breaking under the weight of these loops. Enter NVIDIA Dynamo.
At a Glance
 The Agentic AI Bottleneck
The Agentic AI Bottleneck
 The Agentic AI Bottleneck
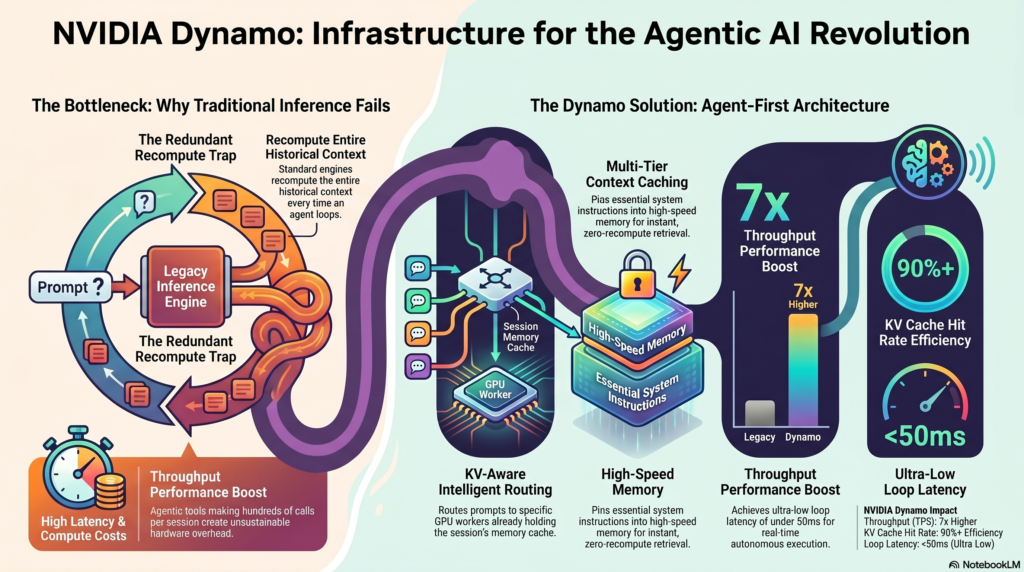
The Agentic AI BottleneckBuilding autonomous systems exposes a massive structural flaw in current large language model (LLM) deployments: Traditional inference was never built for agentic coding.
When a standard chatbot answers a prompt, it makes a single API call. However, when an agentic tool operates—such as analyzing a desktop UI, writing code, executing it, reading the error logs, and rewriting it—it makes hundreds of calls per session. Every time an agent loops back to evaluate a screen state or verify code, standard inference engines must completely recompute the historical context. This redundancy creates severe compute bottlenecks, driving up latency (Time to First Token) and hardware costs to unsustainable levels.
The Four Pillars of NVIDIA Dynamo
NVIDIA recognized this exact architectural breakdown and rebuilt the inference stack from the ground up. To achieve high-speed autonomous loops, Dynamo replaces standard inference handling with an “Agent-First” infrastructure based on four core pillars:
- KV-Aware Routing: In traditional Kubernetes setups, requests are load-balanced randomly to available GPU workers, forcing the new worker to re-read the entire context window. Dynamo intelligently routes the agent’s prompt to the specific GPU worker that already holds the Key-Value (KV) cache for that exact session. This eliminates redundant processing and token ingestion.
- Agent-Aware Scheduling: Dynamo understands the sequence of agentic loops. Instead of treating every API call as an isolated event, it schedules tasks based on the priority and active state of the agent, preventing costly context-switching delays on the hardware.
- Multi-Tier Caching: Caching isn’t just a basic memory buffer anymore; it’s a deep hierarchy (GPU HBM → System RAM → NVMe). Dynamo permanently “pins” essential context directly into the high-speed cache. Repetitive systemic instructions (like massive system prompts, tool schemas, or UI state maps) are retrieved instantly rather than being recomputed.
- Unified Orchestration: Managing GPU nodes, distributed caching, and routing is consolidated into a single orchestration layer, dramatically simplifying the deployment of multi-agent trees across data centers.
What This Means for Production Architectures
If you are an engineering team orchestrating complex, stateful systems—such as using LangGraph to control a desktop autonomously, or deploying AutoGen for a fleet of coding agents—the compute overhead of re-evaluating the system state at every logical step is your primary barrier to real-time execution.
By replacing legacy infrastructure with NVIDIA Dynamo’s stack, developers are experiencing a total paradigm shift in performance metrics:
The Final Verdict
NVIDIA Dynamo is not just another inference engine update; it is the foundational plumbing required for the Agentic AI revolution. By solving the KV cache fragmentation problem and introducing agent-aware scheduling, NVIDIA has effectively eliminated the hardware friction that has been holding back real-time, multi-agent frameworks.
✅ Pros
- Solves context-recompute bottlenecks natively.
- Massive 7x throughput increase for looping agents.
- KV-Aware routing optimizes GPU utilization instantly.
- Perfect integration for LangGraph and AutoGen.
❌ Cons
- Strictly targeted at Enterprise MLOps; overkill for simple generative apps.
- Requires re-architecting existing cluster orchestration to fully utilize.
- Heavy reliance on the NVIDIA hardware ecosystem.