Managing Token Anxiety: Cost Control for AI Development
G
AI Systems Architect
Industry TrendApril 30, 2026© Gate of AI
As AI coding agents like Cursor and AutoGen take over enterprise development in Q2 2026, a new crisis is emerging for CTOs: the exponential, unpredictable token costs of infinite LLM reasoning loops. Welcome to the era of “Token Anxiety.”
At a Glance
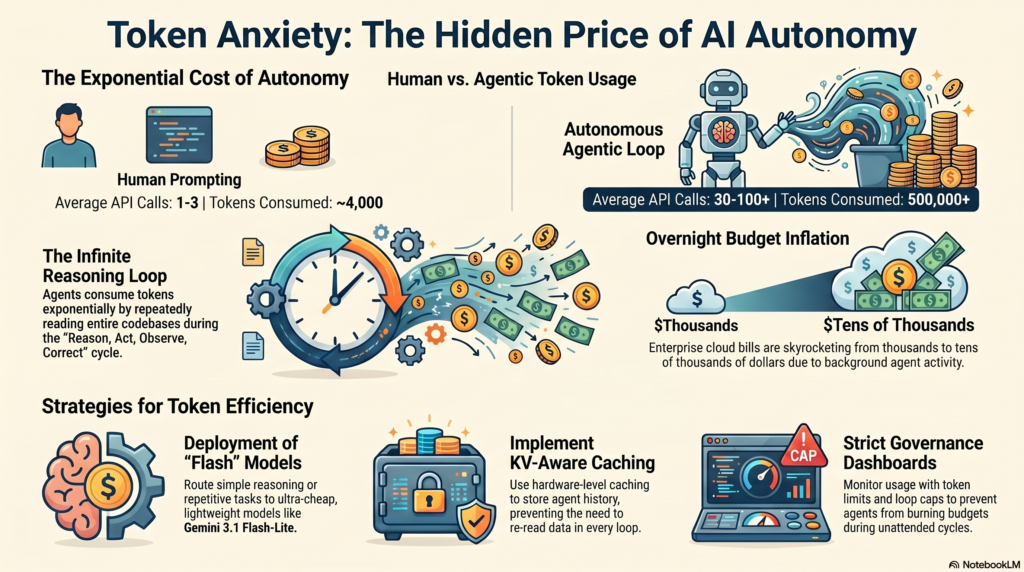
The Hidden Cost of Autonomy
For the past two years, the AI industry has been obsessed with autonomy. We successfully transitioned from passive chatbots that require step-by-step human prompting...
Continue Reading
Log in for free to read the rest of this article and access exclusive AI tools.
Log in / Register