Advanced
⏱ 55 min read
© Gate of AI 2026-04-19
Step out of the terminal and into the GUI. Learn how to orchestrate Vision-Language-Action (VLA) workflows to let AI autonomously navigate your desktop, interact with legacy software, and extract visual data.
Watch Practical Tutorial
Prerequisites
- Python 3.12+ (with
pip) - Anthropic Tier 3+ API Access (for high-rate Claude 4.5 image processing)
- Docker (Strictly required for sandboxing the agent to prevent accidental host system modifications)
- Familiarity with screen coordinate mapping and base64 image encoding
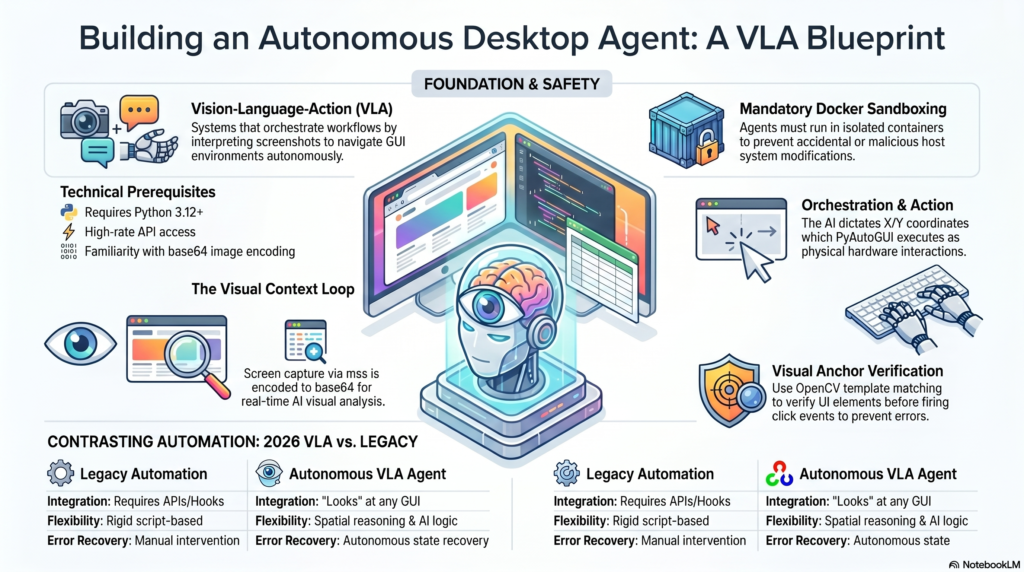
What We’re Building
Standard LLMs interact via text streams. In this 2026 tutorial, we are building a Visual Autonomous Agent. Using Anthropic’s upgraded Claude 4.5 “Computer Use” API architecture, we will create a Python loop that takes a screenshot, sends it to the AI, parses the AI’s intended actions (like moving the mouse to specific X/Y coordinates or typing text), and executes them using PyAutoGUI.
This fundamentally solves the “legacy software” problem, allowing your AI to automate enterprise tools that lack APIs by simply “looking” at the screen and clicking, just like a human.
Setup and Environment Hardening
Because agentic UI control is inherently risky, we strongly advise running this inside a Dockerized Ubuntu container with a virtual frame buffer (Xvfb). For local testing, install the necessary control libraries.
pip install anthropic pyautogui mss opencv-python python-dotenvConfigure your environment variables. Never run this script with root privileges on your primary machine.
# .env file
ANTHROPIC_API_KEY=sk-ant-your-api-key-here
SAFE_MODE=enabled # Custom flag to require human confirmation before clicks
Step 1: The Visual Context Loop
The agent needs “eyes.” We use mss to capture the screen rapidly and encode it into base64, which is the standard format required by the 2026 multimodal vision endpoints.
import mss
import base64
import pyautogui
from PIL import Image
import io
def capture_screen_base64():
with mss.mss() as sct:
# Capture primary monitor
monitor = sct.monitors[1]
sct_img = sct.grab(monitor)
# Convert to standard PIL Image
img = Image.frombytes("RGB", sct_img.size, sct_img.bgra, "raw", "BGRX")
# Downscale slightly to save tokens and reduce latency
img.thumbnail((1280, 720))
buffered = io.BytesIO()
img.save(buffered, format="JPEG", quality=85)
return base64.b64encode(buffered.getvalue()).decode('utf-8'), img.size
Step 2: Defining the “Computer Use” Tool
We configure the Anthropic client,...
Continue Reading
Log in for free to read the rest of this article and access exclusive AI tools.
Log in / Register